Was zählt? Warum die richtige Auswertung in Studien zu Therapien so wichtig ist
Wenn Daten in der Auswertung fehlen, können falsche Schlussfolgerungen entstehen.

Manchmal steckt der Teufel im Detail – bei klinischen Studien zum Beispiel in der Auswertung. Und wie so oft lohnt hier ein genauer Blick.
Zeugnistag. Dein Kind kommt freudestrahlend nach Hause und verkündet „Ein glattes 2er-Zeugnis“. Du freust dich natürlich mit – aber nur so lange, bis du dir das Zeugnis mal genauer anschaust: „Aber was ist hier mit den beiden Vierern in Mathe und Englisch?“. „Ach, das sind nur Ausreißer, die zählen ja nicht.“
Szenenwechsel: Berufliches Fortbildungsseminar. Zehn Minuten nach Beginn stehen zwei Teilnehmerinnen auf und gehen. Offensichtlich hatten sie sich unter dem ausgeschriebenen Thema etwas anderes vorgestellt. Kann ja passieren. Wie üblich werden die Teilnehmer*innen am Ende der Veranstaltung nach ihrer Bewertung gefragt. Und die fällt sehr positiv aus.
Das Wichtigste in Kürze
Selbst randomisierte, kontrollierte, verblindete Studien können zu verzerrten Ergebnissen führen, wenn die Auswertung nicht die Daten aller Teilnehmenden berücksichtigt. Wenn eine Studie als „Beweis“ für die Wirksamkeit eines Mittels zitiert wird, ist es deshalb wichtig, genau hinzusehen.
Was zählt?
In den beiden Beispielen wird es schnell deutlich: Die Bewertungen sind nicht besonders aussagekräftig. Denn wichtige Teile fehlen – und hier sind es ausgerechnet die negativen Ergebnisse. Ähnliches kann bei klinischen Studien auch passieren: Dass das Forschungsteam nicht alle Teilnehmenden mit auswertet. Und auch bei Studien, die eigentlich sonst die höchsten Qualitätsstandards für zuverlässiges Wissen erfüllen: mit einer Kontrollgruppe [1], zufälliger Zuteilung der Teilnehmenden auf die Gruppen [2] und Verblindung aller Beteiligten [3]. Das Problem dabei: Wird nur ein Teil der Daten ausgewertet, ergibt sich ein verzerrtes Bild – also ganz genau das Gegenteil von gesichertem Wissen.
Was dahinter steckt, können wir schnell auflösen: Oft ist es kein Betrug, sondern eine Mischung aus Pech und Schlamperei. Denn in klinischen Studien ist es fast schon an der Tagesordnung, dass nicht alles so läuft wie geplant: Dann vergessen Patient*innen, ihre Tabletten einzunehmen. Oder sie kommen nicht zur vorgesehenen Untersuchung, weil es ihnen in der Terminplanung weggerutscht ist. Oder sie beschließen, nicht länger an der Studie teilzunehmen – zum Beispiel weil sie die erhoffte Linderung ihrer Beschwerden nicht wahrnehmen. Oder weil sie keine Lust mehr auf die Nebenwirkungen haben, die ihrer Meinung nach mit der Studienmedikation zusammenhängen. Und das alles endet dann damit, dass in der Studie wichtige Daten fehlen.
Verzerrte Ergebnisse
Jetzt könnte man natürlich argumentieren: Wenn das in beiden Studiengruppen gleichermaßen passiert, ist das doch gar nicht so schlimm. Hat man eben ein paar weniger Daten für die Auswertung zur Verfügung. Allerdings ist es nicht ganz so einfach, denn oft gibt es einen Zusammenhang zwischen Studienabbruch und den getesteten Medikamenten (oder anderen Behandlungen).
Schauen wir uns dazu nochmal die Beispiele von oben an: Die beiden Noten, die beim Durchschnitt-Berechnen rausgelassen wurden, waren nicht irgendwelche – sondern die beiden schlechtesten. Im Seminar sind nicht beliebige Teilnehmer*innen gegangen – sondern diejenigen, denen die Veranstaltung überhaupt nicht gefallen hat. Und in einer klinischen Studie sind es dann vielleicht diejenigen, die die getesteten Mittel nicht vertragen oder denen sie keine spürbare Linderung verschaffen.
Und ignoriert man dann die fehlenden Daten, bekommt man ein verzerrtes Ergebnis. Lässt man die Daten von den vorzeitig ausgeschiedenen Patient*innen weg, verändert sich dadurch letztlich die Zusammensetzung der beiden Gruppen, die verglichen werden sollen. Und dann ist der Vergleich nicht mehr fair [4].
Bonus für ganz Interessierte
Hast du Lust, ein ganz berühmtes Beispiel zum Auswertungsproblem kennen zu lernen und noch mehr zu erfahren? Dann lies einfach hier weiter. Oder reicht es dir schon? Dann scrolle einfach zum nächsten Abschnitt „Aufwand nötig?“.
In den 1970er Jahren wurde eine Studie veröffentlicht, die Behandlungsoptionen für Menschen mit einem hohen Risiko für Schlaganfall testete. Bei den Patient*innen waren die Halsschlagadern verengt, so dass das Gehirn immer mal wieder nicht ausreichend durchblutet wurde. In der Studie sollten zwei Therapiemethoden verglichen werden: Operation versus eine Behandlung mit Medikamenten. Das Ergebnis schien nach vier Jahren recht eindeutig: Danach erlitten in der Gruppe mit der Operation wesentlich weniger Menschen einen Schlaganfall [5].
Umso größer war die Überraschung, als sich ein anderes Forschungsteam die Studie rund zehn Jahre später nochmal genauer ansah: Den Wissenschaftlern fiel auf, dass in der Auswertung der Operationsgruppe einige Patient*innen fehlten. Nämlich diejenigen, die nach der Zuteilung auf die Gruppen, aber vor Beginn der Nachbeobachtungszeit verstorben waren oder in dieser Zeit einen Schlaganfall hatten. Und das waren in der Operationsgruppe wesentlich mehr als in der Gruppe mit der Arzneimittel-Behandlung. Erst die faire Auswertung – nämlich mit allen, die der jeweiligen Behandlungsgruppe zugeteilt wurden – förderte wichtige Erkenntnisse zutage: Dass nämlich auch die Operation selbst sowie die Wartezeit bis zur Operation negative Effekte hatte. Das führte in der Summe dazu, dass mit der fairen Auswertung auf einmal kein Vorteil der Operation mehr zu erkennen war [6].
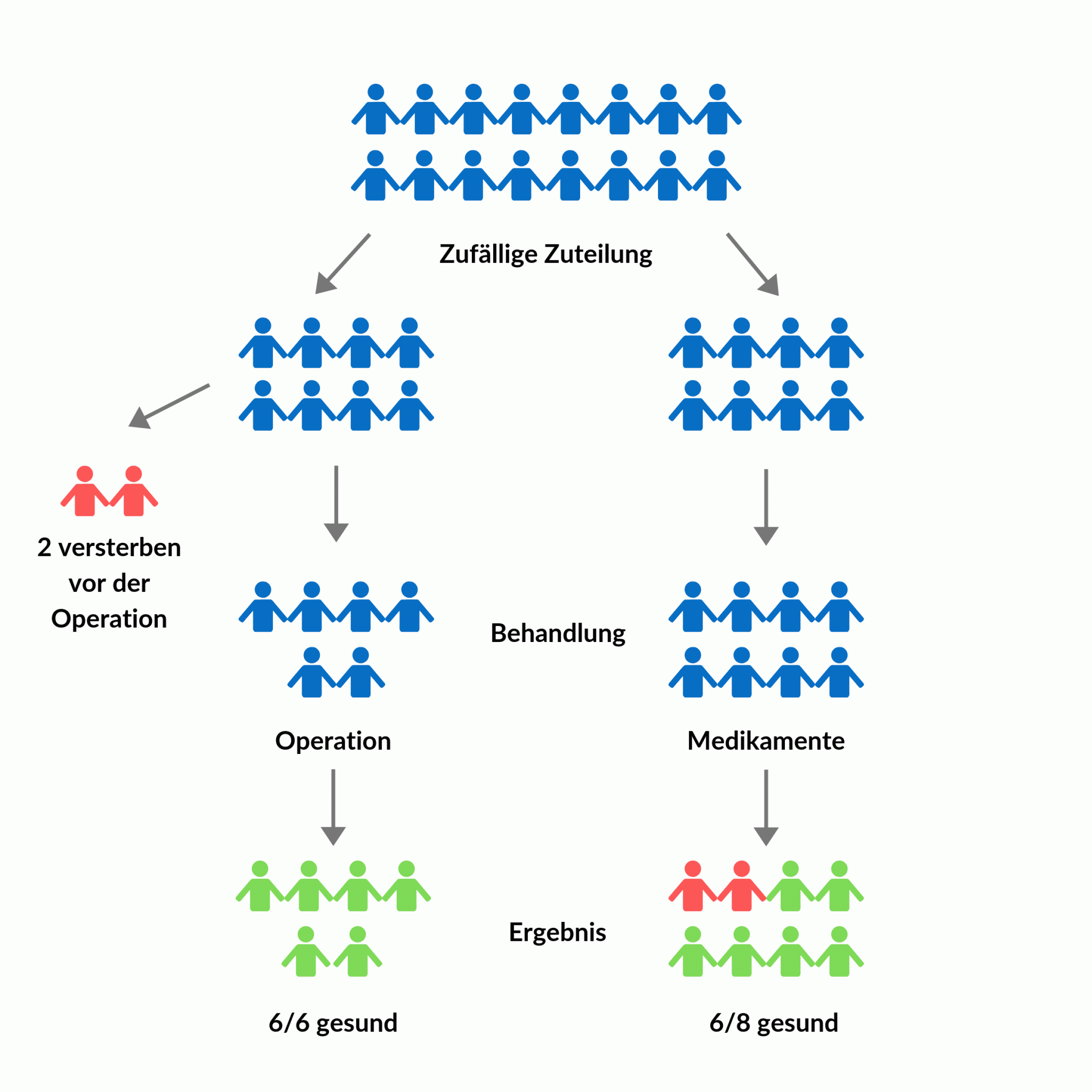
In der Abbildung (vereinfachte Darstellung der Studie) kannst du auch erkennen, wie es zu den verzerrten Ergebnissen kommen konnte: Zähle mal das Schicksal der blauen Figuren in den beiden Gruppen nach. Wenn du nur die Ebene des Ergebnisses anschaust, gibt es in der Operationsgruppe einen höheren Anteil von Figuren mit positivem Ergebnis (grün) als in der Gruppe mit den Medikamenten: Mit Operation sind es 6/6, also 100 Prozent, mit Medikamenten nur 6/8, also 75 Prozent. Da erscheint die Operation also erfolgsversprechender. Wenn du aber den gesamten Studienverlauf betrachtest, findest du in der Operationsgruppe ebenfalls zwei Figuren mit negativem Ergebnis (rot) – die sind allerdings schon vorab ausgeschieden. Trotzdem müssen sie mitgezählt werden, um das „echte“ Ergebnis der Studie rauszukriegen. Und dann gibt es keinen Unterschied mehr zwischen den Gruppen.
Willst du dir das Ganze nochmal in Ruhe anhören? Dann empfehlen wir dir diese Podcast-Episode:
Aufwand nötig
Gesichertes Wissen kann also in der Regel nur entstehen, wenn wirklich alle Daten von allen Teilnehmer*innen mit in die Auswertung fließen – und zwar jeweils in den Gruppen, denen die Menschen zu Beginn der Studie zugeteilt wurden. Im Fachjargon bezeichnet man diese Art der Auswertung auch als „intention to treat“-Analyse oder kurz als „ITT“ [7].
Puh, ganz schön aufwendig. Ja, aber es lohnt sich. Das legen zumindest systematische Untersuchungen [9] nahe, die die Ergebnisse von Studien mit unterschiedlichen Auswertemethoden verglichen haben. Wenn die Forschungsteams von der ITT-Analyse abweichen, kann es unvorhersehbare Folgen haben: Manchmal wird der Therapieeffekt überschätzt, manchmal unterschätzt und manchmal dreht es sich sogar um, welche der beiden Behandlungsmethoden besser erscheint.
Lust auf ein Quiz?
In den letzten vier Artikeln in unserer Rubrik „Gesichertes Wissen“ hast du eine Menge über Kontrollgruppen, Randomisierung, Verblindung und die richtige Auswertung lesen können. Alles nur graue Theorie? Keineswegs! Denn diese Prinzipien kannst du auch benutzen, wenn du eine Studie zu einer wichtigen Frage machen willst, die die Menschheit beschäftigt: Bleibt Sekt tatsächlich länger frisch, wenn du ihn mit einem Löffel im Flaschenhals in den Kühlschrank stellst?
Bevor du dich ins Experimentieren stürzt, würden wir gerne von dir wissen: Wie würdest du eine solche Studie planen, damit du dich auf die Ergebnisse tatsächlich verlassen kannst? Schreib uns bei Twitter oder Facebook – wir sammeln alle Einreichungen und diskutieren dann das beste Studiendesign.
Anmerkungen, Quellen und weiterführende Literatur
[1] In diesem Artikel auf Plan G kannst du nachlesen, warum es für zuverlässiges Wissen so wichtig ist, Behandlungen zu vergleichen, und warum Erfahrungswerte trügen können.
[2] Kontrolle ist gut – aber außerdem braucht es auch wirklich faire Vergleiche. Was Unterschiede in den Startbedingungen ausmachen können, erfährst du in diesem Beitrag auf Plan G.
[3] Nichts sehen, nichts hören – und deshalb mehr wissen: So lässt sich der Nutzen von Verblindung in klinischen Studien kurz beschreiben. Klingt paradox? Das Rätsel löst sich sicher schnell bei der Lektüre dieses Artikels auf Plan G.
[4] Dieser Artikel beleuchtet sehr ausführlich, welche Konsequenzen es hat, wenn Teilnehmende bei der Auswertung ausgeschlossen werden, und differenziert dabei auch, an welcher Stelle der Studie das passiert: Schulz KF, Grimes DA. Schlupflöcher in den Stichproben randomisierter Studien: Ausgeschlossene, Verlorene und Abtrünnige. ZEFQ 2006; 100:467–473
[5] Hier kannst du die Original-Studie nachlesen: Fields W et al. Joint study of extracranial arterial occlusion. JAMA 1970;211:1993–2003 (leider auf Englisch und hinter der Paywall)
[6] Diese Publikation nimmt die Auswertung der Studie genau unter die Lupe und zeigt die Fehler auf: Sackett DL, Gent M. Controversy in counting and attributing events in clinical trials. NEJM 1979, 301:1410–1412 (leider auf Englisch und hinter der Paywall)
[7] Dieser Beitrag taucht noch tiefer in die Hintergründe der Intention-to-treat-Analyse ab. Er beleuchtet auch, welche alternativen Auswertemethoden es gibt, welche Probleme dabei auftreten können und wann sie eventuell doch gerechtfertigt sind: Kleist P. Das Intention-to-treat-Prinzip. Schweiz Med Forum 2009; 9:450–453
[8] Sehr ausführlich und detailliert beschreibt dieser Artikel, was bei fehlenden Daten sinnvollerweise zu tun ist (auf Englisch, aber frei zugänglich). Jacobsen J et al. When and how should multiple imputation be used for handling missing data in randomised clinical trials – a practical guide with flowcharts. BMC Med Res Methodol. 2017; 17:162.
[9] Die Untersuchung befasst sich außerdem noch mit anderen Qualitätsmerkmalen guter Studien und welche Auswirkungen sich tatsächlich beobachten lassen. Der Artikel ist auf Englisch, aber frei zugänglich. Page MJ, Higgins JPT, Clayton G, Sterne JAC, Hróbjartsson A, Savović J (2016) Empirical Evidence of Study Design Biases in Randomized Trials: Systematic Review of Meta-Epidemiological Studies. PLoS ONE 11(7): e0159267